以 Python 實作 Concordancer
每次接近學期末的時候,寫程式癮就會開始發作 (可能是不想面對無趣的期末報告),這時候腦袋會蹦出許多很有趣的想法,然後就會迫不及待地想將這些想法實作出來。這次(2019 年末) 的程式癮刺激來源是實驗室的雲端硬碟裡的某個 (版權封閉) 中文語料庫,雖然該語料庫已有很好的搜尋界面,但我就是想 reinvent the wheel,自己手刻出一個 concordancer。不為了什麼,就只是因為這件事本身就很有樂趣。
初步嘗試:for loop… forever
我本來並沒有太大的雄心壯志,就只想快速弄出個程式界面方便我查找 concordance,想說使用 NLTK concordance 應該很快就可以弄出我想的東西。但 NLTK concordance 只能使用 word form (或 pattern) 去搜尋 concordance,我的需求卻是要能使用 word form 或 PoS tag 搜尋語料庫 (類似 Corpus Query Langauge1,但不用這麼複雜)。但要自己用 Python 實作這個功能也頗簡單,於是我就自己手刻了這個功能。然而事實證明我太過天真了。語料庫的大小約 1000 萬個 token,而每次搜尋時,我的程式使用 for 迴圈跑過整個語料,因此要花非常非常非常久的時間才能完成搜尋。對於非資訊背景出生的我,第一次體驗 $O(n)$ 是件不可忽視的問題以及 Database 存在的必要性。
重新規劃: Database + Python + Vue
為了解決上述問題我暫時擱置了這個專案 (寒假開始到春節期間) 去學習必備的一些知識2,最後比較有系統地重新規劃了這個 concordancer 的架構:
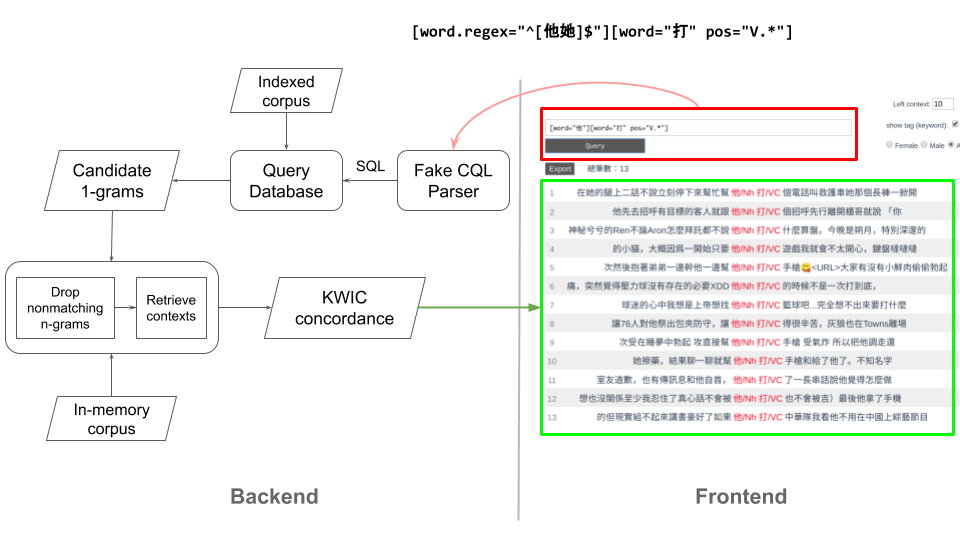
這個新的架構分成前3、後端,前端不是本文的重點 (原始碼在此),就不細談。這邊直接舉一個實例說明這個 concordancer 如何運作:
首先,使用者在前端輸入一個搜尋的字串 (keyword),這個字串需符特定的格式:
[token 1][token 2][token 3]。每對中括號代表一個 token,中括號內則是描述此 token 的特徵,如 word form 與 PoS tag,例如[word="打" pos="V.*"]即是要搜尋 word form 為打且詞類為動詞4 的 token。這裡的例子使用[word.regex="^[他她]$"][word="打" pos="V.*"],下方的幾個例子都是符合這個搜尋的 2-gram:他/Nh 打/VC她/Nh 打/VC
[word.regex="^[他她]$"][word="打" pos="V.*"]在傳給後端後,會先經過一個 parser 處理,讓後端可以將這個 query 轉換成 SQL 去搜尋 database。在搜尋時,這邊僅會在 DB 中以其中一個 token 的資訊進行搜尋,並回傳所有符合的 token 於語料庫中的位置 (所在文件之 id、第幾個句子、token 於句子中的次序)。這些 token 是可能符合 keyword pattern 的「候選者」 ,讓接下來的 n-gram 比對可以更快速 (search space 從整個語料庫減少到只剩這些「候選者」所組成的 n-gram)。透過這些 token 的位置資訊,可以找出含有該 token 的 n-gram。例如,假設這裡使用
[word="打" pos="V.*"]在 DB 當中搜尋,取得結果後,可以再比對此 token 左邊的 token 是否符合[word.regex="^[他她]$"]。若符合,則保留此 2-gram,並取得該 2-gram 左右的 context,作為未來要回傳給使用者的 KWIC concordance。跑完所有的「候選者」token,即可取得整個語料庫內,符合 keyword pattern 的 concordance。接下來僅需將資料轉換成 JSON 格式再傳到前端即可。
Database 設計
下圖是 Database5 的 table 設計,共有 3 個 table:
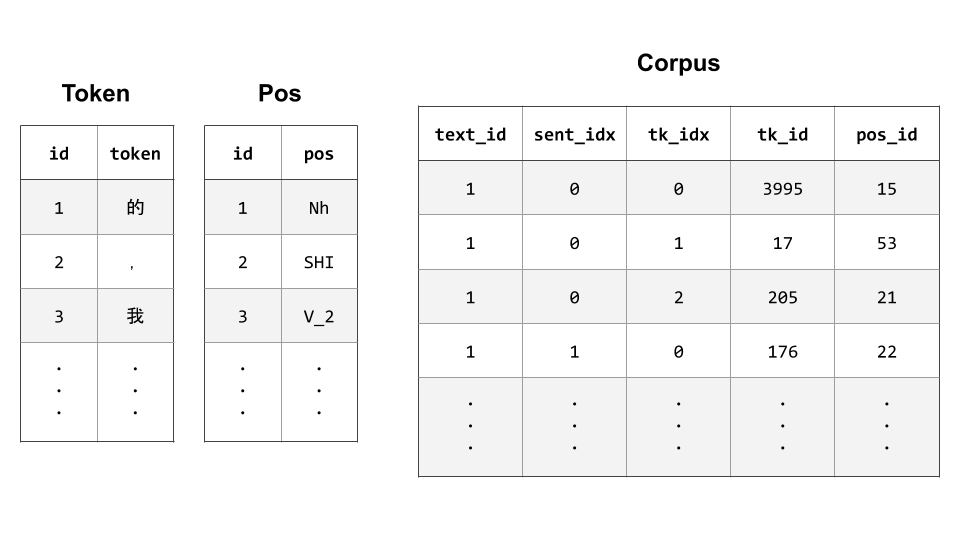
- Token: 將語料庫中的每種 token (即 type) 對應至 id。如此搜尋單一 token 的 word form 時,即可搜尋此較小的 table (列數等於語料庫中 type 的數量),而不用跑過整個語料庫。
- Pos: 將語料庫中的每種 PoS tag 對應至 id。同上,可以快速找出符合的 token。
- Corpus: 保留語料庫 token 位置資訊的 table。搜尋完 Token 以及 Pos 兩 table 之後,即可透過 token 與 pos id 在 Corpus 裡找到符合的列 (e.g.,
tk_id == 3(我) 且pos_id == 1(Nh)。這些列裡面含有這個 token 於語料庫中的位置 (text_id,sent_idx,tk_idx)。
原始碼 / 使用語料庫
這個專案一開始是使用版權封閉的語料庫製作,因此語料庫的資料並未放在 GitHub,但後端的原始碼仍放在 liao961120/kwic-backend。
為了讓這個專案至少能被使用,我另外爬了 Dcard 作為語料 (500 多萬詞,大小約平衡語料庫的一半),並包成 docker image,方便有興趣的人使用。要搜尋 Dcard 語料庫僅需依照下方的步驟:
取得 docker image (僅第一次需執行)
1docker pull liao961120/dcard執行後端 (執行後,請等待 cmd 出現
Corpus Loaded的字串)1docker run -it -p 127.0.0.1:1420:80 liao961120/dcard前往 https://kwic.yongfu.name 使用前端界面
一開始曾想過直接使用現成的 corpus framework,例如 CWB, BlackLab 等。但一方面研究這些 framework 要花許多精力,且因為研究的都是別人做好的 API,不容易學到比較低階、處理語料的問題。 ↩︎
快速掃過 CS50 的前 5 堂課 (我還是不會 C/C++)、複習之前不怎麼認真看待的 SQL Database以及閱讀 SQLite 關於 indexing 的說明文件 (這最重要)。 ↩︎
雖然本來不打算做前端,但由於花了大量時間學習 Database 的概念,多花個幾小時刻個前端相比之下簡單許多 (這邊前端的功能不多)。 ↩︎
這裡的語料是經中研院 ckiptagger 斷詞,可於此檢視其詞類標記集。 ↩︎
建立資料庫以及索引的原始碼位於
liao961120/dcard-corpus/indexCorp.py。 ↩︎